
We currently offer the File Transfer Protocol (FTP) as the main interface to the website files located on our systems. In addition we support encrypted FTP (Implicit and Explicit) if you need additional security when using FTP to transmit data. You can use FTP to upload and download your website files using the FTP login information that was provided in your welcome email (contact us if you lost this information). The FTP client software we suggest for our customers is “FileZilla“, which is available for multiple Operating Systems. The only prerequisite we have is that “Persistent Mode” is turned on, which is normally the default setting.
We do not offer a control panel with website disk usage reports that is available on a global basis due to security and availability concerns. If you wish to have a disk usage report available for your website, you can easily use FTP to upload your own disk usage report software. We currently suggest the following software for disk usage reports:
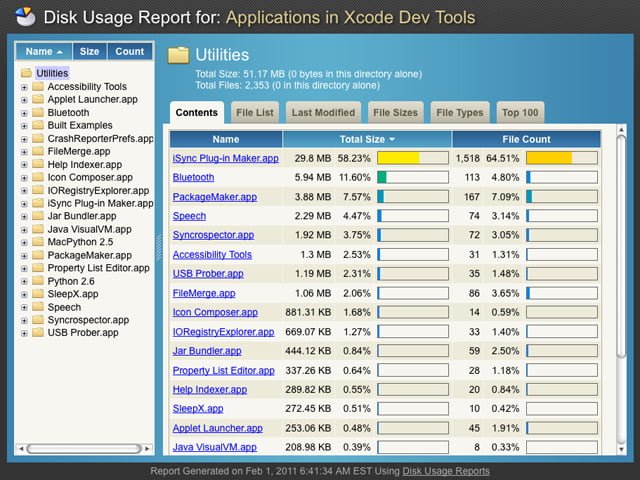
Disk Usage Reports is a free Ajax space usage reporter with an easy-to-install explorer for remotely viewing disk usage on a web server. Its “rich client” layout and actions make it accessible to any end-user for a variety of reports. Only PHP (4 or 5) is necessary, no database needed.
 (No Ratings Yet)
(No Ratings Yet)We currently offer the File Transfer Protocol (FTP) as the main interface to the website files located on our systems. In addition we support encrypted FTP (Implicit and Explicit) if you need additional security when using FTP to transmit data. You can use FTP to upload and download your website files using the FTP login information that was provided in your welcome email (contact us if you lost this information). The FTP client software we suggest for our customers is “FileZilla“, which is available for multiple Operating Systems. If you want a mount point or drive letter so it looks like a local drive using FTP, then check out these software packages:
The only prerequisite we have is that “Passive Mode” is turned on, which is normally the default setting. We suggest using FTP with SSL so the connection is encrypted for security.
We do not offer a web based file manager that is available on a global basis due to security and availability concerns. If you wish to have a file manager available for your website, you can easily use FTP to upload your own file manager. Here is a list of 7 examples of file managers that are available:
1. EXTPLORER
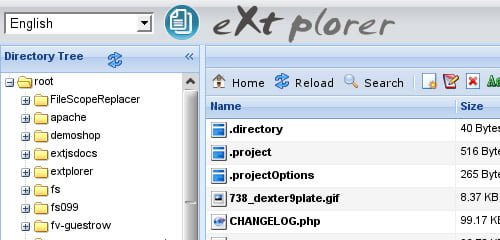
eXtplorer is a web-based File Manager. You can use it to. Features include:
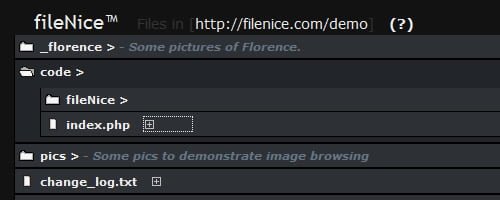
fileNice is a free php file browser, particularly useful if you have a ‘dump’ folder on your server where you regularly upload files and you want to be able to see what’s there.
File Thingie is a small web-based file manager written in PHP. It is intended for those who need to give others access to a part of their server’s file system when FTP is not practical. Through File Thingie you and your users get access to the most common functions:
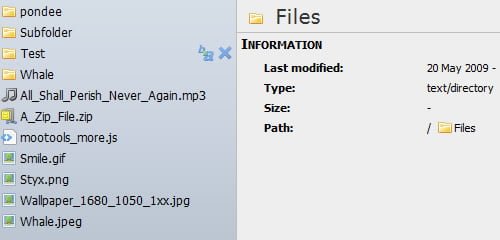
A MooTools based File-Manager for the web that allows you to (pre)view, upload and modify files and folders via the browser. Features include:
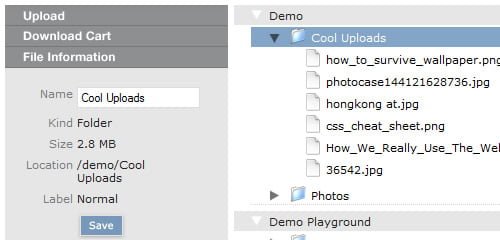
Relay is a wonderful piece of ajax code written with the aid of the prototype ajax toolkit. It does a wonderful job of uploading / downloading and managing files on your private server, let’s check out some of its features:
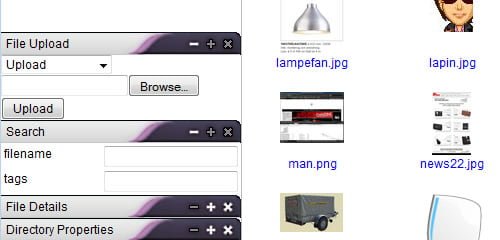
KFM is an online file manager which can be used on its own, or as a plugin for a rich-text editor such as FCKeditor or TinyMCE. KFM is Open Source, and you are free to use it in any project, whether free or commercial. Let’s check out some of its features: drag-and-drop everything, icon-view, list-view, plugins, image manipulations, slideshows, easy installation and upgrades, syntax-highlighting text editor, search engine, tagging, multi-lingual. plugins for mp3 playback, video playback.
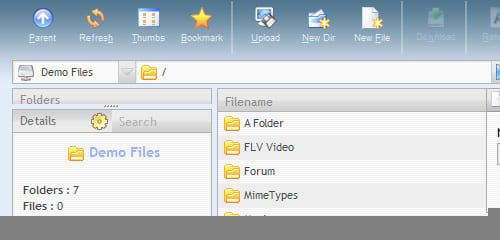
AjaXplorer is a free Ajax file manager with an easy-to-install file explorer for remotely managing files on a web server. Its “rich client” layout and actions make it accessible to any end-user for a variety of purposes: file management/sharing, photo gallery, code browsing, etc. Only PHP (4 or 5) is necessary, no database needed.
(No Ratings Yet)When you retrieve emails from a POP3 email account, the emails are deleted from the Mail Server by default after they are downloaded to your computer. However, if you want to check your emails from multiple computers, you must configure Mail Client to not delete the emails on your Mail Server. This scenario is most common for people who want to check their home Internet service provider (ISP) email account from work and download the emails for permanent storage on their home computer.
When you leave emails on your Mail Server, you can choose from several options to delete your emails. To make your choice, you need to consider several factors about your email usage, such as how long you want the emails to be accessible from multiple computers and the storage limits imposed by your email server administrator. If you exceed your storage limit, you might be unable to receive new emails or might be charged additional fees.
In Outlook, it allows you to select a time duration for leaving email on the Mail Server.
1. On the ‘Tools’ menu, click ‘E-mail Accounts’.
2. Click ‘View or change existing e-mail accounts’, and then click ‘Next’.
3. Select your email account, and then click ‘Change’.
4. Click ‘More Settings’.
5. Click the ‘Advanced’ tab, and under ‘Delivery’, select the ‘Leave a copy of messages on the server’ check box.
6. Under ‘Internet E-mail Settings’ dialog box, select one of the following options:
a) Remove from server after x days
Emails are downloaded to your computer but remain on the Mail Server for the number of days that you specify. This is the most common setting for people who want to read their emails at work but also download them for permanent storage on their home computer. We recommend that you choose the smallest number of days that suits your needs. The longer you leave emails on your Mail Server, the greater the risk of exceeding your mailbox size quota.
b) Remove from server when deleted from ‘Deleted Items’
Emails are downloaded to your computer but also remain on the Mail Server indefinitely until you delete the emails in Outlook and empty the ‘Deleted Items’ folder. Just deleting the email doesn’t remove the email from the Mail Server.
*** If you do not select either check box, emails are left on the server indefinitely. You can eventually exceed your mailbox quota, unless you connect to the Mail Server from another computer that has Outlook configured to remove emails from the Mail Server.
(No Ratings Yet)
What’s the difference?
The main difference, as far as we are concerned here, is the way in which IMAP or POP controls your e-mail inbox.
When you use IMAP you are accessing your inbox on the central mail server. IMAP does not actually move messages onto your computer. You can think of an e-mail program using IMAP as a window to your messages on the server. Although the messages appear on your computer while you work with them, they remain on the central mail server.
POP does the opposite. Instead of just showing you what is in your inbox on the mail server, it checks the server for new messages, downloads all the new messages in your inbox onto your computer, and then deletes them from the server. This means that every time you use POP to view your new messages, they are no longer on the central mail server.
IMAP makes it easier to view mail from home, work, and other locations
Because IMAP leaves all of your messages on the central mail server, you can view these messages from any location with Internet access. This means the e-mail inbox you view from home will be the same one you see at work.
Since POP downloads new messages to your computer and removes them from the server, you will not be able to see those new messages on another computer when you check your inbox. Those messages exist only on the computer that downloaded them using POP. If you loose this computer, then you will also loose all your emails that were downloaded to it using POP.
However, if you use IMAP and create e-mail folders on the server, these folders are accessible from anywhere you read your e-mail using IMAP. If you use POP and create e-mail folders, they are stored locally, and you cannot access these folders from anywhere except the computer on which you created them.
POP can create problems if you alternate between it and IMAP. There is an option in many POP e-mail programs to leave copies of the messages on the server, but this option has complications. When you leave copies of the messages on the server, then access your e-mail using WebMail or another IMAP e-mail client, the POP client may create duplicate messages next time it accesses the inbox; you will see each of the messages more than once, and you will have to clean out (delete) the unwanted ones.
You may want to keep local copies
While using IMAP to save e-mail on the central mail server is recommended, there are reasons to have local copies of messages (messages downloaded to the computer, as with POP). Fortunately, IMAP allows you to keep local copies of all your messages. The option of local copies is useful when you are connecting from a dial-up connection. You may want to download your messages, then disconnect from the Internet and work with your mail offline. Please note that while you are working offline, you cannot send or receive mail. You need to be connected to the Internet to do those tasks.
(No Ratings Yet)
This guide was built to serve as a comprehensive resource to using .htaccess. If you are completely new to using .htaccess — you might want to start with the first chapter “.htaccess Basics” below.
If you are searching for specific code samples or tutorials look at the navigation on the right-hand side of this page to jump directly to sub-sections within this page.
.htaccess Basics
What is .htaccess?
The .htaccess file is a configuration file that affects how a webserver responds to various requests. It is supported by several webservers, including the popular Apache software used by mosy commercial web hosting providers.
.htaccess files operate at the level of a directory, allowing them to override global configuration settings of .htaccess directives higher in the directory tree.
Why is it called .htaccess?
These files were first used to control user access on a per-directory basis.
Using a subset of Apache’s http.conf settings directives, it allowed a system administrator to restrict access to individual directories to users with a name and password specified in an accompanying .htpasswd file.
While .htaccess files are still used for this, they are also used for a number of other things which we’ll cover in this guide.
Where is the .htaccess file?
In theory, every folder (directory) on your server could have one. Generally, though, there is one in your web root folder — that’s the folder that holds all the content of your website, and is usually labeled something like Public_HTML or www.
If you have a single directory that contains multiple website subdirectories, there will usually be an .htaccess file in the main root (Public_HTML) directory and also one in each subdirectory (/sitename).
Why can’t I find my .htaccess file?
On most file systems, file names that begin with a dot ( . ) are hidden files. This means they are not typically visible by default.
But they aren’t hard to get to. Your FTP client or File Manager should have a setting for “show hidden files.” This will be in different places in different programs, but is usually in “Preferences”, “Settings”, or “Folder Options.” Sometime you’ll find it in the “View” menu.
What if I don’t have an .htaccess file?
First of all, make sure that you have turned on “show hidden files” (or its equivalent), so that you can be sure you actually don’t have one. Often, .htaccess files are created automatically, so you will usually have one. But this isn’t always the case.
If you really don’t have one, you can easily create one:
Start a new file in a plain text editor.
Save it in ASCII format (not UTF-8 or anything else) as .htaccess
.
Make sure that it isn’t htaccess.txt or something like that. The file should have only the name .htaccess with no additional file extension.
Upload it to the appropriate directory via FTP or your browser-based file manager.
Error Handling
Using .htaccess files to specify error documents is very simple, one of the simplest things you can do with this feature.
What is an error code?
When a request is made to a web server, it tries to respond to that request, usually by delivering a document (in the case of HTML pages), or by accessing an application and returning the output (in the case of Content Management Systems and other web apps).
If something goes wrong with this, an error is generated. Different types of errors have different error codes. You are probably familiar with the 404 error, which is returned if the document cannot be found on the server.
There are many other error codes that a server can respond with.
Client Request Errors
400 — Bad Request
401 — Authorization Required
402 — Payment Required (not used yet)
403 — Forbidden
404 — Not Found
405 — Method Not Allowed
406 — Not Acceptable (encoding)
407 — Proxy Authentication Required
408 — Request Timed Out
409 — Conflicting Request
410 — Gone
411 — Content Length Required
412 — Precondition Failed
413 — Request Entity Too Long
414 — Request URI Too Long
415 — Unsupported Media Type.
Server Errors
500 — Internal Server Error
501 — Not Implemented
502 — Bad Gateway
503 — Service Unavailable
504 — Gateway Timeout
505 — HTTP Version Not Supported.
What happens by default?
If you don’t specify any type of error handling, the server will simply return the message to the browser, and the browser will display a generic error message to the user. This is usually not ideal.
Specifying Error Documents
Create an HTML document for each error code you want to handle. You can name these whatever you like, but it’s helpful to name them something that will help you remember what they’re for, like not-found.html or simply 404.html.
Then, in the .htaccess file, specify which document to use with each type of error.
ErrorDocument 400 /errors/bad-request.html
ErrorDocument 401 /errors/auth-reqd.html
ErrorDocument 403 /errors/forbid.html
ErrorDocument 404 /errors/not-found.html
ErrorDocument 500 /errors/server-err.html
Notice that each directive is placed on its own line.
And that’s it. Very simple.
Alternatives to .htaccess for error handling
Most Content Management Systems (CMS) like WordPress and Drupal, and most web apps, will have their own way of handling most of these errors codes.
Password Protection With .htaccess
The original purpose of .htaccess files was to restrict access to certain directories on a per-user basis (hence the name, hyper text access). So we’ll look at that first.
.htpasswd
Usernames and passwords for the .htaccess system are stored in a file name .htpasswd.
These are stored each on a single line, in the form:
username:encryptedpassword
for example:
johnsmith:F418zSM0k6tGI
It’s important to realize that the password stored in the file isn’t the actual password used to log in. Rather it is a cryptographic hash of the password.
This means that the password has been run through an encryption algorithm, and the result is stored. When a user logs in, the plain-text password is entered and run through the same algorithm. If the input is the same, the passwords match and the user is granted access.
Storing passwords this way makes them more secure — if someone were to gain access to your .htpasswd file, they would only see the hashed passwords, not the originals. And there is no way to reconstruct the originals from the hash — it is a one way encryption.
Several different hashing algorithms can be used:
Secure Algorithms — Use one of
these
bcrypt — This is the most secure, but also the slowest to compute. It is supported by Apache and Nginx.
md5 — This is the default hashing algorithm used by current versions of Apache. It is not supported by Nginx.
Insecure Algorithms — Do not use
these
crypt() — This used to be the default hashing function, but it is not very secure.
SHA and Salted SHA.
Creating usernames and passwords on the command line
You can create an .htpasswd file, and add username-password pairs to it, directly from the command line or SSH terminal.
The command for dealing with the .htpasswd file is simply htpasswd.
To create a new .htpasswd file, use the command with the -c option (for create), then type the path to the directory (not the URL, the actual path on the server). You can also include a user you want to add.
> htpasswd -c /usr/local/etc/.htpasswd johnsmith
This creates a new .htpasswd file in the /etc/ directory, and adds a record for a user named johnsmith. You will be prompted for a password, which will also be stored, using the md5 encryption.
If there is already an .htpasswd file at the specified location, a new one is not created — the new user is simply appended to the existing file.
If you’d prefer to use the bcrypt hashing algorithm, use the -b option.
Password hashing without the command line
If you don’t feel comfortable using the command line or SSH terminal (or if you don’t have access to it for some reason), you can simply create an .htpasswd file and populate it using a plain text editor, and upload it via FTP or file manager.
But then you’ll need to encrypt your passwords somehow, since the htpasswd command was taking care of that for you.
There are many .htpasswd encryption utilities available online. The best one is probably the htpasswd generator at Aspirine.org.
This gives you several options for hashing algorithm and password strength. You can simply copy-and-paste the output from there into your .htpasswd file.
Where to keep your .htpasswd file
You don’t need to have a separate .htpasswd file for every .htaccess file. In fact, you shouldn’t. Under most normal circumstances, you should have one for your entire web hosting account or main server directory.
The .htpasswd file should not be in a publicly accessible directory — not Public_HTML or www or any subdirectory. It should be above those, in a folder that is only accessible from the server itself.
How to use .htpasswd with .htaccess
Each directory can have its own .htaccess file, with its own set of users which are allowed to access it.
If you want any one (including non-logged-in users) to access the directory and its files, simply do nothing — that is the default.
To restrict access you need to add the following to the .htaccess file:
AuthUserFile /usr/local/etc/.htpasswd
AuthName “Name of Secure Area”
AuthType Basic
The
In the above example, any valid user can access files. If you want to restrict access to a specific user or few users, you can name them.
AuthUserFile /usr/local/etc/.htpasswd
AuthName “Name of Secure Area”
AuthType Basic
require user janedoe
The group file, which could be named (for example) .htgroups looks like this:
admin: johnsmith janedoe
staff: jackdoe cindysmith
Then you can specify it in your .htaccess file:
AuthUserFile /usr/local/etc/.htpasswd
AuthGroupFile /usr/local/etc/.htgroup
AuthName “Admin Area”
AuthType Basic
Using .htaccess and .htpasswd to resrict access to certain files on your server only really makes sense if you have a lot of static files. The feature was developed when web sites were usually a collection of HTML documents and related resources.
If you are using a content management system (CMS) like WordPress or Drupal, you can use the built-in user management features to restrict or grant access to content.
Enabling Server Side Includes (SSI)
What are Server Side Includes?
SSI, or Server Side Includes, is a light-weight scripting language used primarily to embed HTML documents into other HTML documents.
This makes it easy to re-use common elements, such as headers, footers, sidebars, and menus. You can think of it as a precursor to today’s templating and content management systems.
SSI also has conditional directives (if, else, etc.) and variables, making it a complete, if somewhat hard to use, scripting language. (Typically, any project more complicated than a handful of includes will cause a developer to choose a more robust language like PHP or Perl.)
Enabling SSI
Some web hosting servers will have Server Side Includes enabled by default. If not, you can enable it with your .htaccess file, like so:
AddType text/html .shtml
AddHandler server-parsed .shtml
Options Indexes FollowSymLinks Includes
This should enable SSI for all files that have the .shtml extension.
SSI on .html files
If you want to enable SSI parsing on .html files, you can add a directive to accomplish that:
AddHandler server-parsed .html
The benefit of doing this is that you can use SSI without letting the world know you are using it. Also, if you change implementations in the future, you can keep your .html file extensions.
The downside of this is that every .html file will be parsed with SSI. If you have a lot of .html files that don’t actually need any SSI parsing, this can introduce a lot of unneeded server overhead, slowing down your page load times and using up CPU resources.
SSI on your Index page
If you don’t want to parse all .html files, but you do want to use SSI on your index (home) page, you’ll need to specify that in your .htaccess file.
That’s because when the web server is looking for a directory’s index page, it looks for index.html, unless you tell it otherwise.
If you aren’t parsing .html files, you’ll need your index page to be named index.shtml for SSI to work, and your server doesn’t know to look for that by default.
To enable that, simply add:
DirectoryIndex index.shtml index.html
This alerts the web server that the index.shtml file is the main index file for the directory. The second parameter, index.html is a backup, in case index.shtml can’t be found.
IP Blacklisting and IP Whitelisting
You can use .htaccess to block users from a specific IP address (blacklisting). This is useful if you have identified individual users from specific IP addresses which have caused problems.
You can also do the reverse, blocking everyone except visitors from a specific IP address (whitelisting). This is useful if you need to restrict access to only approved users.
Blacklisting by IP
To block specific IP addresses, simply use the following directive, with the appropriate IP addresses:
order allow,deny
deny from 111.22.3.4
deny from 789.56.4.
allow from all
The first line states that the allow directives will be evaluated first, before the deny directives. This means that allow from all will be the default state, and then only those matching the deny directives will be denied.
If this was reversed to order deny,allow, then the last thing evaluated would be the allow from all directive, which would allow everybody, overriding the deny statements.
Notice the third line, which has deny from 789.56.4. — that is not a complete IP address. This will deny all IP addresses within that block (any that begin with 789.56.4).
You can include as many IP addresses as you like, one on each line, with a deny from directive.
Whitelisting by IP
The reverse of blacklisting is whitelisting — restricting everyone except those you specify.
As you may guess, the order directive has to be reversed, so that that everyone is first denied, but then certain addresses are allowed.
order deny,allow
deny from all
allow from 111.22.3.4
allow from 789.56.4.
Domain names instead of IP addresses
You can also block or allow users based on a domain name. This can be help block people even as they move from IP address to IP address. However, this will not work against people who can control their reverse-DNS IP address mapping.
order allow,deny
deny from example.com
allow from all
This works for subdomains, as well — in the previous example, visitors from xyz.example.com will also be blocked.
Block Users by Referrer
A referrer is the website that contains a link to your site. When someone follows a link to a page on your site, the site they came from is the referrer.
This doesn’t just work for clickable hyperlinks to your website, though.
Pages anywhere on the internet can link directly to your images (“hotlinking”) — using your bandwidth, and possibly infringing on your copyright, without providing any benefit to you in terms of traffic. They can also hotlink to your CSS files, JS scripts, or other resources.
Most website owners are okay with this when happens just a little bit, but sometimes this sort of thing can turn into abuse.
Additionally, sometimes actual in-text clickable hyperlinks are problematic, such as when they come from hostile websites.
For any of these reasons, you might want to block requests that come from specific referrers.
To do this, you need the mod_rewrite module enabled. This is enabled by default for most web hosts, but if it isn’t (or you aren’t sure) you can usually just ask your hosting company. (If they can’t or won’t enable it, you might want to think about a new host.)
The .htaccess directives that accomplish referrer-based blocking rely on the mod_rewrite engine.
The code to block by referrer looks like this:
RewriteEngine on
RewriteCond % ^http://.*example.com [NC,OR]
RewriteCond % ^http://.*anotherexample.com [NC,OR]
RewriteCond % ^http://.*onemoreexample.com [NC]
RewriteRule .* – [F]
This is a little tricky, so lets walk through it.
The first line, RewriteEngine on, alerts the parser that a series of directives related to rewrite is coming.
The next three lines each block one referring domain. The part you would need to change for your own use is the domain name (example) and extension (.com).
The backward-slash before the .com is an escape character. The pattern matching used in the domain name is a regular expression, and the dot means something in RegEx, so it has to be “escaped” using the back-slash.
The NC in the brackets specifies that the match should not be case sensitive. The OR is a literal “or”, and means that there are other rules coming. (That is — if the URL is this one or this one or this one, follow this rewrite rule.)
The last line is the actual rewrite rule. The [F] means “Forbidden.” Any requests with a referrer matching the ones in the list will fail, and deliver a 403 Forbidden error.
Blocking Bots and Web Scrapers
One of the more annoying aspects of managing a website is discovering that your bandwidth is being eaten up by non-human visitors — bots, crawlers, web scrapers.
These are programs that are designed to pull information out of your site, usually for the purpose of republishing it as part of some low-grade SEO operation.
There, of course, legitimate bots — like those from major search engines. But the rest are like pests that just eat away at your resources and deliver no value to you whatsoever.
There are several hundred bots identified. You will never be able to block all of them, but you can keep the activity down to a dull roar by blocking as many as you can.
Here is a set of rewrite rules which will block over 400 known bots, compiled by AskApache
Specifying a Default File for a Directory
When a request is made to a web server for a URL which does not specify a file name, the assumption built into most web servers is that the URL refers to a directory.
So, if you request http://example.com, Apache (and most other web servers) is going look in the root directory for the domain (usually /Public_HTML or something similar, but perhaps /example-com) for the default file.
The default file, by default, is called index.html. This goes way back to the beginning of the internet when a website was just a collection of documents, and the “home” page was usually an index of those documents.
But you might not want index.html to be the default page. For example, you might need a different file type, like index.shtml, index.xml, or index.php.
Or you might not think of your home page as an “index,” and want to call it something different, like home.html or main.html.
Setting the Default Directory Page
.htaccess allows you to set the default page for a directory easily:
DirectoryIndex [filename here]
If you want your default to be home.html it’s as easy as:
DirectoryIndex home.html
Setting Multiple Default Pages
You can also specify more than one DirectoryIndex:
DirectoryIndex index.php index.shtml index.html
The way this works is that the web server looks for the first one first. If it can’t find that, it looks for the second one, and so on.
Why would you want to do this? Surely you know which file you want to use as your default page, right?
Remember that .htaccess affects its own directory, and every subdirectory until it is overridden by a more local file. This means that an .htaccess file in your root directory can provide instructions for many subdirectories, and each one might have its own default page name.
Being able to place those rules in a single .htaccess file in the root means that you don’t have to duplicate all the other directives in the file at every directory level.
URL Redirects and URL Rewriting
One of the most common uses of .htaccess files is URL redirects.
URL redirects should be used when the URL for a document or resource has changed. This is especially helpful if you have reorganized your website or changed domain names.
301 vs. 302
From a browser standpoint, there are two types of redirects, 301 and 302. (These numbers refer to the error code generated by the web server.)
301 means “Permanently Moved,” while 302 means “Moved Temporarily.” In most cases, you want to use 301. This preserves any SEO equity the original URL had, passing it on to the new page.
It also will cause most browsers to update their bookmarks. Most browsers will also cache the old-to-new mapping, so they will simply request the new URL when a link or user attempts to access the original. If the URL has changed permanently, these are all desirable results.
There’s very little reason to use 302 redirects, since there’s usually very little reason to temporarily change a URL. Changing a URL ever is undesirable, but is sometimes necessary. Changing it temporarily, with the plan to change it back later, is a bad idea and is almost always avoidable.
All the examples in this section will use the 301 redirect.
Redirect vs. Rewrite
There are two different ways to “change” a URL with .htaccess directives — the Redirect command and the mod_rewrite engine.
The Redirect command actually sends a redirect message to the browser, telling it what other URL to look for.
Typically, the mod_rewrite tool “translates” one URL (the one provided in a request) into something that the file system or CMS will understand, and then handles the request as if the translated URL was the requested URL.
When used this way, the web browser doesn’t notice that anything happened — it just receives the content it asked for.
The mod_rewrite tool can also be used to produce 301 redirects that work the same way as the Redirect command, but with more options for rules — mod_rewrite can have complex pattern matching and rewriting instructions, which Redirect cannot take advantage of.
Basic Page Redirect
To redirect one page to another URL, the code is:
Redirect 301 /relative-url.html http://example.com/full-url.html
This single-line command has four parts, each separated with a single space:
The Redirect command
The type of redirect ( 301 – Moved Permanently )
The relative URL of the original page
The full and complete URL of the new page.
The relative URL is relative to the directory containing the .htaccess file, which is usually the web root, or the root of the domain.
So if http://example.com/blog.php had been moved to http://blog.example.com, the code would be:
Redirect 301 /blog.php http://blog.example.com
Redirecting a large section
If you have moved your directory structure around, but kept your page names the same, you might want to redirect all requests for a certain directory to the new one.
Redirect 301 /old-directory http://example.com/new-directory
Redirecting an entire site
What if you entire site has moved to a new URL? Easy.
Redirect 301 / http://newurl.com
Redirecting www to non-www
Increasingly, websites are moving away from the www subdomain.
It’s never really been necessary, but it was a holdover from the days when you most people who operated a website were using a server to store lots of their own documents, and the www or “world wide web” directory was used for content they wanted to share with others.
These days, some people use it, and some people don’t. Unfortunately, some users still automatically type www. in front of every URL out of habit. If you’re not using www, you want to make sure that these requests land in the right place.
To do this, you’ll need to use the mod_rewrite module, which is probably already installed on your web host.
Options +FollowSymlinks
RewriteEngine on
RewriteCond % ^www.example.com [NC]
RewriteRule ^(.*)$ http://example.org/$1 [R=301,NC]
Be careful!
A lot of other .htaccess and mod_rewrite guides offer some variation of the following code to accomplish this:
Options +FollowSymlinks
RewriteEngine on
RewriteCond % !^example.com [NC]
RewriteRule ^(.*)$ http://example.org/$1 [R=301,NC]
Do you see the problem with that?
It redirects all subdomains to the primary domain. So not just www.example.com, but also blog.example.com and admin.example.com and anything else. This is probably not the behavior you want.
Redirecting to www
But what if you are using the www subdomain?
You should probably set up a redirect to make sure people get to where they’re trying to go. Especially now that fewer people are likely to automatically add that www to the beginning of URLs.
You just reverse the above code.
RewriteEngine On
RewriteCond % ^example.com [NC
RewriteRule ^(.*) http://www.website.com/$1 [R=301,NC]
Something you shouldn’t do
Several guides on .htaccess redirects include instructions on how to make 404 errors redirect to the home page.
This is a good example of how just because you can do something, it doesn’t mean you should do something.
Redirecting 404 errors to the site’s homepage is a terrible idea. It confuses visitors, who can’t figure out why they are seeing the front page of a site instead of a proper 404 error page.
All websites should have a decent 404 page which clearly explains to the user that the content couldn’t be found and, ideally, offers some search features to help the user find what they were looking for.
Why use .htaccess instead of other alternatives?
You can set up redirect in PHP files, or with any other type of server-side scripting. You can also set them up within your Content Management System (which is basically the same thing).
But using .htaccess is usually the fastest type of redirect. With PHP-based redirects, or other server-side scripting languages, the entire request must be completed, and the script actually interpreted before a redirect message is sent to the browser.
With .htaccess redirects, the server responds directly to the request with the redirect message. This is much faster.
You should note, though — some content management systems actually manage redirects by updating the .htaccess programatically. WordPress, for example, has redirect plugins that work this way. (And WP’s pretty URL system does this as well.)
This gives you the performance of using .htaccess directly, while also giving you the convenience of management from within your application.
Hiding Your .htaccess File
There is no reason that someone should be able to view your .htaccess file from the web. It is never a needed document.
Moreover, there are some big reasons you should definitely not want people to see your .htaccess file. The biggest issue is that if you are using an .htpasswd file, its location is spelled out in the .htaccess file. Knowing where to find it makes it easier to find.
Moreover, as a general rule, you don’t want to provide the public with details about your implementation.
Rewrite rules, directory settings, security — all of the things that you use .htaccess for — it is a good security practice to hide all of this behind-the-scenes at your web server. The more a hacker can learn about your system, the easier it is to compromise it.
It is very easy to hide your .htaccess file from public view. Just add the following code:
order allow,deny
deny from all
Enabling MIME types
MIME types are file types. They’re called MIME types because of their original association with email (MIME stands for “Multipurpose Internet Mail Extensions”). They aren’t just called “file types” because MIME implies a specific format for specifying the file type.
If you’ve ever authored an HTML document, you’ve like specified a MIME type, even if you didn’t know it:
(No Ratings Yet)
Since we are a company based and operating out of Riverside California, we like to highlight the awards and recognition Riverside has received as a technology based area. This re-enforces why Riverside is a great place for your Mobile Office based business, and why we are proud to help serve the businesses and residents of Riverside California.
| Awards and recognition Riverside has received: |
|
(No Ratings Yet)
We have compiled a list of various software that we suggest might be beneficial for you and your business for day to day operations and to interact the most efficiently with our services. We based our selection criteria on software reliability, features, and lastly the ability of the software to work on multiple operating systems. Most of the software listed is free when used for personal use. The list is as follows:
Libre Office – This is a productivity suite that includes a Word Processor, Spreadsheet, Presentation, Drawing, and Database. The Word Processor can be used to directly edit files that are stored in the files tab of our Mobile Office on-line application (requires Mobile Office transfer agent is enabled, and JAVA is installed on computer). Software is available for Windows, Mac, and Linux.
Opera – Web browser software that allows you to view web pages. Opera in our own tests was one of the fastest and most reliable browsers. In addition it provides extra privacy features built in such as an Adblocker and VPN client. This software can be used to view your website, or any website on the Internet. Software is available for Windows, Mac, and Linux.
WhatsApp – Online chat software that allows you to communicate with other users. WhatsApp in our own tests was one of the most feature rich and most secure, with its end-to-end encryption support. Software is available for Windows, Mac OS X, iOS, Android, and Web.
FileZilla – FTP software that allows you to transfer files to and from various computer FTP servers. This software can be used to upload your webpage source code files (or other files) to your web storage area on our web hosting server systems. This software and our servers support encrypted Explicit or Implicit FTP over SSL for enhanced security of file transferring. Software is available for Windows, Mac, and Linux.
eM Client – E-mail software that allows you to manage your e-mail from various computer e-mail servers. This software will allow you to receive and compose e-mail on our e-mail hosting server systems. Additionally you can sync Contacts (CardDAV), Calendar events (CalDAV), and Tasks (CalDAV) with our email hosting. Software is available for Windows, Mac OS X, Google Android, and Apple iOS. eM Client does require a paid license for business use or to access its advanced features. If your looking for a open source email client that is also available for Linux, then we suggest Thunderbird.
Our various on-line tools to interface with our services are also available at: https://www.imageway.com/tools
If you have any other issues or comments, don’t hesitate to contact customer support.
 (1 votes, average: 3.00 out of 5)
(1 votes, average: 3.00 out of 5)
If you or a user forgets their password, the administrator can do the following to change any domain users email:
1> In a web browser goto: https://mail.YOURDOMAIN.COM” (where YOURDOMAIN.COM is the domain you linked the hosting to).
2> Click the “Domain Admin” button, and use “postmaster@YOURDOMAIN.COM” as the username, and put in the password that was sent to you in your welcome email.
3> Once you are logged in move over to the “Domain Admin” heading and click the “User Accounts” option.
4> Click the “Search accounts” button.
5> Click on the account name you want to change the password for.
6> Where it says “password”, put in the new password.
7> Click the “Save User” button.
8> Make sure at the top you see “+OK” to verify it was saved.
If you don’t see “+OK“, then fix the password based on the response at the top. It might not allow a password if it is too short or easy to guess.
You can repeat the above steps for as many users as you wish.
If you have any other issues or comments, don’t hesitate to contact customer support.
Thanks.
Imageway Staff
Rate This Entry:
(No Ratings Yet)![]() Loading...
Loading...
If you are trying to change your email account password do the following:
1> In a web browser goto: https://mail.YOURDOMAIN.COM” (where YOURDOMAIN.COM is the domain you linked the hosting to).
2> Click the “Webmail” button, and use “EMAIL@YOURDOMAIN.COM” as the username, and put in your current password.
3> Click the “options” and then “Preferences” at the top right.
4> Click the “Change password” button.
5> This will allow you to change your current password.
You can repeat the above steps anytime to change your email account password at anytime.
If you have any other issues or comments, don’t hesitate to contact customer support.
Thanks.
Imageway Staff
Rate This Entry:
(No Ratings Yet)![]() Loading...
Loading...
When your quota size limit is reached for your email account, or for your whole domain name, you will receive an email that says “WARNING! Mailbox at or near capacity”. If the quota is reached for an email account, you can adjust the size of the email quota by doing the following:
1) In a web browser goto: https://mail.YOURDOMAIN.COM” (where YOURDOMAIN.COM is the domain you linked the hosting to).
2) Click the “Domain Admin” button, and use “postmaster@YOURDOMAIN.COM” as the username, and put in the password that was sent to you in your welcome email.
3) Once you are logged in move over to the “Domain Admin” heading and click the “User Accounts” option.
4) Click the “Search accounts” button.
5) Click on the account name you want to change the quota for.
6) Where it says “Disk Quota”, use the dropdown to change the size. (example: 500mb).
7) Click the “Save User” button.
YOUR DONE!
The amount of quota space you have available for your whole domain is based on the account level you have purchased. You put limits on each account so no one person takes up all the space for the domain as a whole. If you are using all the space for your whole domain and need to increase it, please contact support.
If you have any other issues or comments, don’t hesitate to contact customer support.
(No Ratings Yet)All rights reserved. Copyright © 2000-2025 Imageway, LLC.
 information technology into operations to better serve constituents and businesses. Recognized cities have continued to realize operational objectives despite financial challenges, strategically investing to maximize dollars and effectively conduct the business of government.
information technology into operations to better serve constituents and businesses. Recognized cities have continued to realize operational objectives despite financial challenges, strategically investing to maximize dollars and effectively conduct the business of government.
 ave continued to realize operational objectives despite financial challenges, strategically investing to maximize dollars and effectively conduct the business of government.
ave continued to realize operational objectives despite financial challenges, strategically investing to maximize dollars and effectively conduct the business of government.